· engineering · 9 min read
Small on-device vision models and what they let you build
Small vision models, fine-tuned for specific jobs, can now run on a phone with accuracy that used to need a server. Here is what that changes for image-driven apps.

For a while, if you wanted software that could look at a photo and tell you something useful about it, you were sending that photo to a server. The model lived in the cloud. Your app took the picture, uploaded it, waited, and showed the result. That worked, but it came with a list of compromises: a network round trip, a dependency on connectivity, ongoing per-request costs, and a copy of your user’s image sitting on someone else’s infrastructure.
That arrangement is changing. A new generation of small vision models, often fine-tuned for specific jobs, can now run directly on a phone or laptop with accuracy that used to need server-class hardware. We’ve been doing this kind of custom AI work on the text side for a while, building fine-tuned models for tasks like named entity recognition, and the same approach now applies to vision. It is worth explaining what changed and where it actually helps.
What a small vision model can do
A vision model takes an image, usually with a text prompt or question, and returns a result: a description, a classification, extracted text, a count of objects, an answer to a question about the picture. The category usually called “vision language models” combines an image encoder, which turns a picture into tokens, with a small language model that turns those tokens plus your prompt into an answer.
The catch used to be that doing this well required large models, and large models needed servers. That is no longer a given. Two things have shifted.
First, the architecture work. Researchers have published efficient image encoders specifically built for high-resolution images on small devices. Apple’s FastVLM is one prominent example: its FastViTHD encoder produces far fewer visual tokens than a standard transformer while keeping the detail accuracy depends on. The result is a model that runs in near real-time on an iPhone.
Second, fine-tuning. Even a small base model, trained further on the right data, can outperform a much larger general-purpose model on a specific task. Supervised fine-tuning (SFT) takes a pre-trained model and continues its training on labelled examples of the exact job you want it to do. We’ve used this approach to build small NER models that hit production accuracy on the narrow domains we trained them for, often matching much bigger general models on those tasks. The same logic applies to vision: pick a small, capable base, fine-tune it on representative data for the actual job, and you get production accuracy on hardware you can ship to a user.
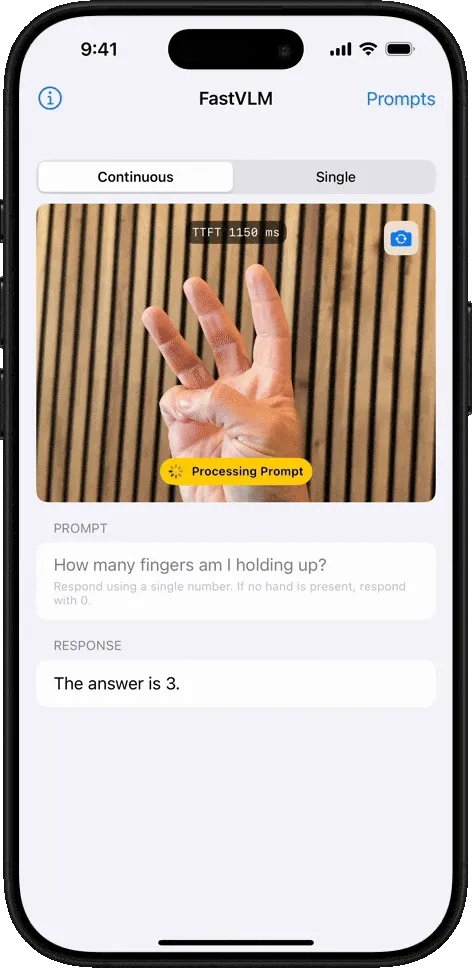
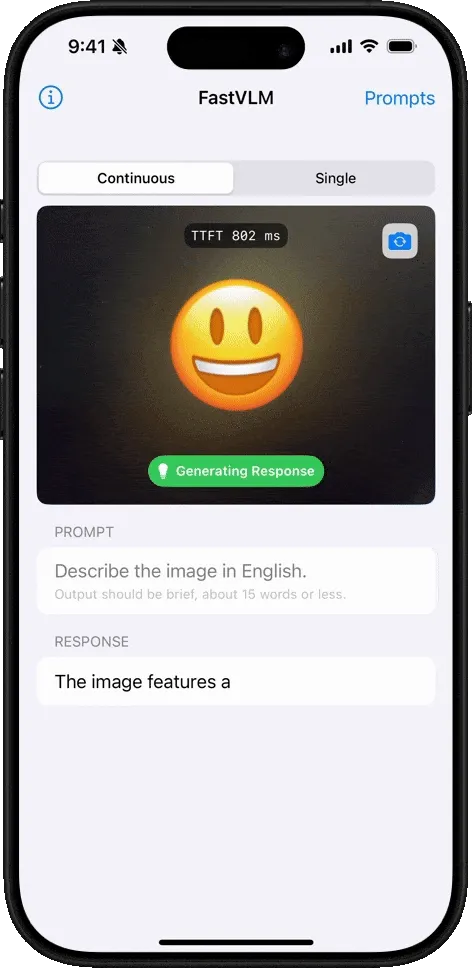
The demo above is FastVLM running locally on an iPhone, counting objects and reading emoji in a live camera feed. We are not pitching FastVLM specifically. What matters is that small visual models, running on a device in real-time, are now realistic for production work.
What changes when the model runs on the device
The speed numbers get the attention. What actually changes the design work is everything that becomes possible once the model runs locally.
Data stays on the device
When the model runs locally, the image never leaves the phone. For some products this is a nice-to-have. For others it is the entire point. If you are building something that handles medical images, financial documents, identity verification, or anything covered by privacy regulation, “the data never goes to a server” is a much easier story to tell a compliance team than “the data goes to a server but we encrypt it.” It removes a category of risk rather than mitigating it.
It works without a connection
An on-device model does not care whether there is signal. That sounds minor until you think about where image-capture apps actually get used. Warehouse floors, basements, building sites, rural properties, ships, mines. Field workers in those environments lose connectivity constantly, and an app that stalls every time the bars drop is an app they stop trusting. On-device inference means the feature behaves the same in a dead zone as it does on office wifi.
Latency drops
A cloud round trip has a floor. Even on a good connection you are paying for the upload, the queue, the inference, and the download. On-device, there is no upload and no network at all. For anything interactive, like a live camera viewfinder that describes what it sees or flags an issue as you point at it, that difference is the whole experience. You cannot build a responsive camera feature on a model that takes a second and a half to answer.
The cost structure changes
A cloud vision API charges per request. That is fine at low volume and uncomfortable at high volume, and it makes your running costs scale with usage in a direction you usually do not want. A model running on the user’s hardware costs nothing per call. You do the engineering work once. For a product that processes a lot of images, that can be the difference between a feature that pays for itself and one that quietly eats the margin.
Small specialised models can beat big general ones
A general-purpose cloud model has to be good at everything. A small, fine-tuned model only has to be good at one thing. On the task it was trained for, a well-tuned small model often matches or exceeds the larger one and runs in a fraction of the time on a fraction of the hardware. The same reason a specialist tradesperson is faster than a generalist on their own job.
Where this is useful
A few categories are worth designing around.
Field inspection and asset management. An app that lets a worker photograph equipment, a meter, or a defect and get an immediate structured read, with no wait and no connection required. The kind of tool that gets used on a roof or in a plant room where signal is unreliable.
Document and form capture. Reading printed or handwritten text out of a photographed document, on the device, without that document ever being uploaded. Useful for onboarding flows, expense capture, and anything in a regulated industry.
Accessibility. Describing a scene or reading text aloud for a user with low vision. This needs to be fast and it needs to work everywhere, which is what on-device inference provides.
Retail and inventory. Identifying and counting products from a shelf photo, checking stock, scanning labels. This often happens in large buildings with patchy coverage.
Real-time camera features. Anything where the camera is live and the app reacts to what it sees as the user moves it. Translation overlays, guided assembly, visual checks on a production line.
The honest tradeoffs
Small on-device models are not a free win, and we would not pitch them as one.
For the hardest open-ended reasoning tasks, a large cloud model will still give you a better answer. The on-device model is tuned for a different job: fast, accurate handling of a specific task on hardware with a fraction of the power. If you genuinely need to answer arbitrary questions about arbitrary images, you may still want the big model.
They use the device’s resources. A vision model running locally draws on memory and battery, and that needs to be designed for, especially on older phones. Picking the right model size for the job is part of the work.
And you ship and update the model with your app, rather than improving it server-side whenever you like. That is a different release discipline.
For a lot of products the right architecture is a mix. An on-device model handles the common cases where speed and privacy matter, and a cloud model picks up the harder ones when a connection exists. Deciding where that line sits is one of the more interesting parts of the build.
How we approach it
When a client comes to us with an image-driven feature, the on-device option is now on the table in a way it was not a couple of years ago. The questions we work through are practical. How sensitive is the image data. How often will users be offline. How interactive does the feature need to feel. What hardware are the users actually on. What is the volume, and what would a per-request cloud bill look like at scale.
Sometimes the answer is to start with an off-the-shelf small model that already does most of what’s needed. Sometimes the answer is to fine-tune one ourselves on the client’s data, the same way we’ve done for custom named entity recognition on the text side. The pattern is the same in both directions: pick a small, capable base, gather a representative dataset, run supervised fine-tuning until accuracy hits the target, package the model so it runs on the device with acceptable battery and memory cost.
If you have an image-processing feature in mind, or an existing one that depends on a cloud API you’d rather not depend on, we are happy to talk through what running it on-device would look like. The work usually pulls from a mix of what we do on the AI development and mobile app development sides, with the broader custom software work picking up the integration around it.
FAQs
What is a small on-device vision model? A vision model small enough to run on a phone, tablet, or laptop instead of a remote server. It usually pairs an efficient image encoder with a compact language model.
Are small on-device models accurate enough for production? For a well-defined task, yes. A small model fine-tuned on the right data often matches a much larger general-purpose model on that task. For open-ended reasoning across any image, a large cloud model still has an edge.
Does on-device processing mean the app works offline? Yes. If the model runs on the device, image understanding does not need a network connection. The feature behaves the same with or without signal.
What is supervised fine-tuning? Taking a pre-trained model and continuing its training on a labelled dataset of the specific task you want it to do. It is how we get small, specialised models to perform well on a particular job.
Can this run on Android, or only Apple devices? Both. Apple has been visible publishing FastVLM and the MLX tooling, but the broader category of small, efficient vision models is not Apple-only. The right model depends on the target devices, which we scope per project.


